Appendix B Analysis of AlgorithmsThis appendix is an edited excerpt from Think Complexity, by Allen B. Downey, also published by O’Reilly Media (2011). When you are done with this book, you might want to move on to that one. Analysis of algorithms is a branch of computer science that studies the performance of algorithms, especially their run time and space requirements. See http://en.wikipedia.org/wiki/Analysis_of_algorithms. The practical goal of algorithm analysis is to predict the performance of different algorithms in order to guide design decisions. During the 2008 United States Presidential Campaign, candidate Barack Obama was asked to perform an impromptu analysis when he visited Google. Chief executive Eric Schmidt jokingly asked him for “the most efficient way to sort a million 32-bit integers.” Obama had apparently been tipped off, because he quickly replied, “I think the bubble sort would be the wrong way to go.” See http://www.youtube.com/watch?v=k4RRi_ntQc8. This is true: bubble sort is conceptually simple but slow for large datasets. The answer Schmidt was probably looking for is “radix sort” (http://en.wikipedia.org/wiki/Radix_sort)1. The goal of algorithm analysis is to make meaningful comparisons between algorithms, but there are some problems:
The good thing about this kind of comparison that it lends itself to simple classification of algorithms. For example, if I know that the run time of Algorithm A tends to be proportional to the size of the input, n, and Algorithm B tends to be proportional to n2, then I expect A to be faster than B for large values of n. This kind of analysis comes with some caveats, but we’ll get to that later. B.1 Order of growthSuppose you have analyzed two algorithms and expressed their run times in terms of the size of the input: Algorithm A takes 100n+1 steps to solve a problem with size n; Algorithm B takes n2 + n + 1 steps. The following table shows the run time of these algorithms for different problem sizes:
At n=10, Algorithm A looks pretty bad; it takes almost 10 times longer than Algorithm B. But for n=100 they are about the same, and for larger values A is much better. The fundamental reason is that for large values of n, any function that contains an n2 term will grow faster than a function whose leading term is n. The leading term is the term with the highest exponent. For Algorithm A, the leading term has a large coefficient, 100, which is why B does better than A for small n. But regardless of the coefficients, there will always be some value of n where a n2 > b n. The same argument applies to the non-leading terms. Even if the run time of Algorithm A were n+1000000, it would still be better than Algorithm B for sufficiently large n. In general, we expect an algorithm with a smaller leading term to be a better algorithm for large problems, but for smaller problems, there may be a crossover point where another algorithm is better. The location of the crossover point depends on the details of the algorithms, the inputs, and the hardware, so it is usually ignored for purposes of algorithmic analysis. But that doesn’t mean you can forget about it. If two algorithms have the same leading order term, it is hard to say which is better; again, the answer depends on the details. So for algorithmic analysis, functions with the same leading term are considered equivalent, even if they have different coefficients. An order of growth is a set of functions whose asymptotic growth behavior is considered equivalent. For example, 2n, 100n and n+1 belong to the same order of growth, which is written O(n) in Big-Oh notation and often called linear because every function in the set grows linearly with n. All functions with the leading term n2 belong to O(n2); they are quadratic, which is a fancy word for functions with the leading term n2. The following table shows some of the orders of growth that appear most commonly in algorithmic analysis, in increasing order of badness.
For the logarithmic terms, the base of the logarithm doesn’t matter; changing bases is the equivalent of multiplying by a constant, which doesn’t change the order of growth. Similarly, all exponential functions belong to the same order of growth regardless of the base of the exponent. Exponential functions grow very quickly, so exponential algorithms are only useful for small problems. Exercise 1 Read the Wikipedia page on Big-Oh notation at http://en.wikipedia.org/wiki/Big_O_notation and answer the following questions:
Programmers who care about performance often find this kind of analysis hard to swallow. They have a point: sometimes the coefficients and the non-leading terms make a real difference. Sometimes the details of the hardware, the programming language, and the characteristics of the input make a big difference. And for small problems asymptotic behavior is irrelevant. But if you keep those caveats in mind, algorithmic analysis is a useful tool. At least for large problems, the “better” algorithms is usually better, and sometimes it is much better. The difference between two algorithms with the same order of growth is usually a constant factor, but the difference between a good algorithm and a bad algorithm is unbounded! B.2 Analysis of basic Python operationsMost arithmetic operations are constant time; multiplication usually takes longer than addition and subtraction, and division takes even longer, but these run times don’t depend on the magnitude of the operands. Very large integers are an exception; in that case the run time increases with the number of digits. Indexing operations—reading or writing elements in a sequence or dictionary—are also constant time, regardless of the size of the data structure. A for loop that traverses a sequence or dictionary is usually linear, as long as all of the operations in the body of the loop are constant time. For example, adding up the elements of a list is linear: total = 0
for x in t:
total += x
The built-in function sum is also linear because it does the same thing, but it tends to be faster because it is a more efficient implementation; in the language of algorithmic analysis, it has a smaller leading coefficient. If you use the same loop to “add” a list of strings, the run time is quadratic because string concatenation is linear. The string method join is usually faster because it is linear in the total length of the strings. As a rule of thumb, if the body of a loop is in O(na) then the whole loop is in O(na+1). The exception is if you can show that the loop exits after a constant number of iterations. If a loop runs k times regardless of n, then the loop is in O(na), even for large k. Multiplying by k doesn’t change the order of growth, but neither does dividing. So if the body of a loop is in O(na) and it runs n/k times, the loop is in O(na+1), even for large k. Most string and tuple operations are linear, except indexing and len, which are constant time. The built-in functions min and max are linear. The run-time of a slice operation is proportional to the length of the output, but independent of the size of the input. All string methods are linear, but if the lengths of the strings are bounded by a constant—for example, operations on single characters—they are considered constant time. Most list methods are linear, but there are some exceptions:
Most dictionary operations and methods are constant time, but there are some exceptions:
The performance of dictionaries is one of the minor miracles of computer science. We will see how they work in Section B.4. Exercise 2 Read the Wikipedia page on sorting algorithms at http://en.wikipedia.org/wiki/Sorting_algorithm and answer the following questions:
B.3 Analysis of search algorithmsA search is an algorithm that takes a collection and a target item and determines whether the target is in the collection, often returning the index of the target. The simplest search algorithm is a “linear search,” which traverses the items of the collection in order, stopping if it finds the target. In the worst case it has to traverse the entire collection, so the run time is linear. The in operator for sequences uses a linear search; so do string methods like find and count. If the elements of the sequence are in order, you can use a bisection search, which is O(logn). Bisection search is similar to the algorithm you probably use to look a word up in a dictionary (a real dictionary, not the data structure). Instead of starting at the beginning and checking each item in order, you start with the item in the middle and check whether the word you are looking for comes before or after. If it comes before, then you search the first half of the sequence. Otherwise you search the second half. Either way, you cut the number of remaining items in half. If the sequence has 1,000,000 items, it will take about 20 steps to find the word or conclude that it’s not there. So that’s about 50,000 times faster than a linear search. Exercise 3 Write a function called bisection that takes a sorted list and a target value and returns the index of the value in the list, if it’s there, or None if it’s not. Or you could read the documentation of the bisect module and use that! Bisection search can be much faster than linear search, but it requires the sequence to be in order, which might require extra work. There is another data structure, called a hashtable that is even faster—it can do a search in constant time—and it doesn’t require the items to be sorted. Python dictionaries are implemented using hashtables, which is why most dictionary operations, including the in operator, are constant time. B.4 HashtablesTo explain how hashtables work and why their performance is so good, I start with a simple implementation of a map and gradually improve it until it’s a hashtable. I use Python to demonstrate these implementations, but in real life you wouldn’t write code like this in Python; you would just use a dictionary! So for the rest of this chapter, you have to imagine that dictionaries don’t exist and you want to implement a data structure that maps from keys to values. The operations you have to implement are:
For now, I assume that each key only appears once. The simplest implementation of this interface uses a list of tuples, where each tuple is a key-value pair. class LinearMap(object):
def __init__(self):
self.items = []
def add(self, k, v):
self.items.append((k, v))
def get(self, k):
for key, val in self.items:
if key == k:
return val
raise KeyError
add appends a key-value tuple to the list of items, which takes constant time. get uses a for loop to search the list: if it finds the target key it returns the corresponding value; otherwise it raises a KeyError. So get is linear. An alternative is to keep the list sorted by key. Then get could use a bisection search, which is O(logn). But inserting a new item in the middle of a list is linear, so this might not be the best option. There are other data structures (see http://en.wikipedia.org/wiki/Red-black_tree) that can implement add and get in log time, but that’s still not as good as constant time, so let’s move on. One way to improve LinearMap is to break the list of key-value pairs into smaller lists. Here’s an implementation called BetterMap, which is a list of 100 LinearMaps. As we’ll see in a second, the order of growth for get is still linear, but BetterMap is a step on the path toward hashtables: class BetterMap(object):
def __init__(self, n=100):
self.maps = []
for i in range(n):
self.maps.append(LinearMap())
def find_map(self, k):
index = hash(k) % len(self.maps)
return self.maps[index]
def add(self, k, v):
m = self.find_map(k)
m.add(k, v)
def get(self, k):
m = self.find_map(k)
return m.get(k)
Hashable objects that are considered equal return the same hash value, but the converse is not necessarily true: two different objects can return the same hash value.
Since the run time of LinearMap.get is proportional to the number of items, we expect BetterMap to be about 100 times faster than LinearMap. The order of growth is still linear, but the leading coefficient is smaller. That’s nice, but still not as good as a hashtable. Here (finally) is the crucial idea that makes hashtables fast: if you can keep the maximum length of the LinearMaps bounded, LinearMap.get is constant time. All you have to do is keep track of the number of items and when the number of items per LinearMap exceeds a threshold, resize the hashtable by adding more LinearMaps. Here is an implementation of a hashtable: class HashMap(object):
def __init__(self):
self.maps = BetterMap(2)
self.num = 0
def get(self, k):
return self.maps.get(k)
def add(self, k, v):
if self.num == len(self.maps.maps):
self.resize()
self.maps.add(k, v)
self.num += 1
def resize(self):
new_maps = BetterMap(self.num * 2)
for m in self.maps.maps:
for k, v in m.items:
new_maps.add(k, v)
self.maps = new_maps
Each HashMap contains a BetterMap; get just dispatches to BetterMap. The real work happens in add, which checks the number of items and the size of the BetterMap: if they are equal, the average number of items per LinearMap is 1, so it calls resize. resize make a new BetterMap, twice as big as the previous one, and then “rehashes” the items from the old map to the new. Rehashing is necessary because changing the number of LinearMaps
changes the denominator of the modulus operator in
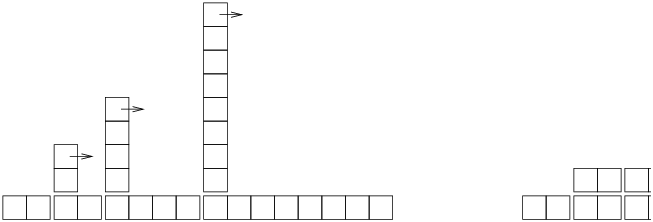
Rehashing is linear, so resize is linear, which might seem bad, since I promised that add would be constant time. But remember that we don’t have to resize every time, so add is usually constant time and only occasionally linear. The total amount of work to run add n times is proportional to n, so the average time of each add is constant time! To see how this works, think about starting with an empty HashTable and adding a sequence of items. We start with 2 LinearMaps, so the first 2 adds are fast (no resizing required). Let’s say that they take one unit of work each. The next add requires a resize, so we have to rehash the first two items (let’s call that 2 more units of work) and then add the third item (one more unit). Adding the next item costs 1 unit, so the total so far is 6 units of work for 4 items. The next add costs 5 units, but the next three are only one unit each, so the total is 14 units for the first 8 adds. The next add costs 9 units, but then we can add 7 more before the next resize, so the total is 30 units for the first 16 adds. After 32 adds, the total cost is 62 units, and I hope you are starting to see a pattern. After n adds, where n is a power of two, the total cost is 2n−2 units, so the average work per add is a little less than 2 units. When n is a power of two, that’s the best case; for other values of n the average work is a little higher, but that’s not important. The important thing is that it is O(1). Figure B.1 shows how this works graphically. Each block represents a unit of work. The columns show the total work for each add in order from left to right: the first two adds cost 1 units, the third costs 3 units, etc. The extra work of rehashing appears as a sequence of increasingly tall towers with increasing space between them. Now if you knock over the towers, amortizing the cost of resizing over all adds, you can see graphically that the total cost after n adds is 2n − 2. An important feature of this algorithm is that when we resize the HashTable it grows geometrically; that is, we multiply the size by a constant. If you increase the size arithmetically—adding a fixed number each time—the average time per add is linear. You can download my implementation of HashMap from http://thinkpython/code/Map.py, but remember that there is no reason to use it; if you want a map, just use a Python dictionary.
|
ContributeIf you would like to make a contribution to support my books, you can use the button below. Thank you!
Are you using one of our books in a class?We'd like to know about it. Please consider filling out this short survey.
|